

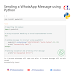
Code:
Solution and Explanantion:
This is a recursive Python function named sum. It calculates the sum of integers from 1 to a given number (num). Let's break it down:
def sum(num)::
This line defines a function named sum that takes one argument, num.
if num == 1::
This is a base case for the recursion. It checks if the input num is equal to 1.
return 1:
If num is indeed 1, it returns 1. This is the base case of the recursion where the sum of integers from 1 to 1 is 1.
return num + sum(num-1):
If num is not equal to 1, it returns the sum of num and the result of calling sum recursively with num-1. This line adds the current value of num to the sum of all integers from 1 to num-1.
print(sum(4)):
This line calls the sum function with the argument 4, meaning it will calculate the sum of integers from 1 to 4.
Let's trace how this works with sum(4):
sum(4) calls sum(3)
sum(3) calls sum(2)
sum(2) calls sum(1)
sum(1) returns 1 (base case)
sum(2) returns 2 + 1 = 3
sum(3) returns 3 + 3 = 6
sum(4) returns 4 + 6 = 10
So, print(sum(4)) will output 10.
























.png)























.png)
.png)














s.PNG)







.png)
.png)












